Генерация цепочек языка. Имея некоторую грамматику, будем использовать правила подстановки. Например, следующая грамматика генерирует все последовательности (цепочки), состоящие из сбалансированных круглых скобок, то есть последовательности, в которых каждой открывающей скобки соответствует закрывающая:
S → SS | (S) | ()
Любую цепочку мы можем преобразовать путем замены любого нетерминального символа на правую часть любого правила подстановки, в которой этот нетерминальный символ имеется в левой части. Посмотрим получение цепочки ( () () ):
- заменяем S по правилу S → (S) и получаем (S);
- заменяем S в (S) по правилу S → SS и получаем (SS);
- заменяем первое S в (SS) по правилу S → () и получаем (()S);
- заменяем S в (()(S)) по правилу S → () и получаем (() () ).
Можно использовать и такую запись вывода:
S → (S) → (SS) → (() (S) → (() ())
Каждый член этого вывода – есть сентенциальная форма.
Формально, язык есть множество сентенциальных форм, которые состоят только из терминальных символов и выводимы из исходного символа грамматики.
Использование формальной грамматики для определения синтаксиса языка программирования важно как для программиста, использующего язык, так и для его разработчика. Это - однозначное понимание: пользователь может получить из нее ответы на сложные вопросы относительно вида программы, пунктуации и структуры. Разработчик может использовать грамматику для того, чтобы определит в данном языке все возможно допустимые структуры программ, с которыми может взаимодействовать транслятор.
Программист и разработчик имеют общее согласованное определение, которое можно использовать для разрешения споров о допустимых синтаксических конструкциях. Формальное определение синтаксиса помогает также устранению незначительных синтаксических различий в отдельных реализациях языка.
Определение того, что данная цепочка – правильная? есть проблема синтаксического анализа или грамматического разбора этой цепочки. Если разбор прошел успешно, то данная цепочка принадлежит указанному языку. Если же не удается провести грамматический разбор с помощью заданных правил грамматики, то она не принадлежит этому языку. Например, цепочка W = Y + (U * V) анализируется с помощью НФБ-грамматики, правила которой представлены в таблице 4.1. Дерево грамматического разбора представлено на рис. 4.3.
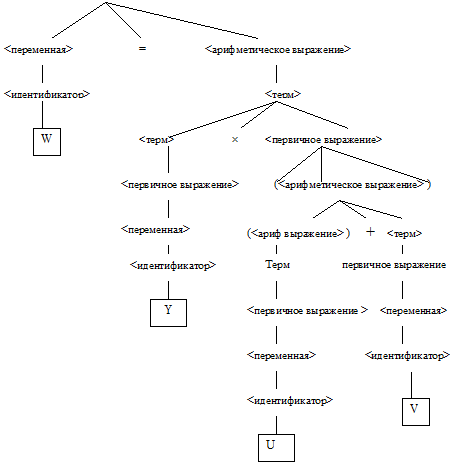
Рис. 4.3. Дерево грамматического разбора для оператора присваивания
Несмотря на простую структуру НФБ-грамматики, она может использоваться для определения синтаксиса большинства языков программирования. Только та область синтаксиса, которая связана с контекстной зависимостью, не может быть определена при помощи этой грамматики. Не могут быть заданы с помощью лишь одной НФБ-грамматики такие ограничения:
- один и тот же идентификатор не может быть описан дважды в одном блоке;
- каждый идентификатор должен быть описан в каком-либо блоке, определяющем область его использования;
- на массив, определенный как двухмерный, нельзя ссылаться с помощью трех индексов.
Ограничения такого рода должны быть определены как дополнение к формальной НФБ-грамматике.
Похожие статьи:
